La eficiencia de un equipo se puede ver afectada por muchos factores, uno de ellos es la estrategia de Git. Si, aunque suene extraño, el simple hecho de la manera en que integramos el código puede impactar la productividad del equipo. Este blog post explica dos estrategias: GitFlow, la estrategia más común, y Trunk-Based Development (TBD), poco conocida pero utilizada por equipos altamente eficientes.
¿Qué entendemos por una git branching strategy? Con este concepto nos referimos a la metodología de creación y actualización de ramas git que implementaremos en la operativa de nuestro equipo. ¿Por qué es necesaria una estrategia de git branching? El principal motivo de establecer una estrategia en equipo es poder efectuar los cambios necesarios que el proyecto demanda de la manera más segura y organizada. Eso no significa que tengamos que ser nosotros mismos los que inventemos estas estrategias. Por suerte, existe mucha bibliografía al respecto y hoy veremos algunas de las más famosas. Trataremos de profundizar en cada una de ellas para que podamos compararlas entre sí fácilmente y elegir cuál nos conviene más para nuestro caso de uso.
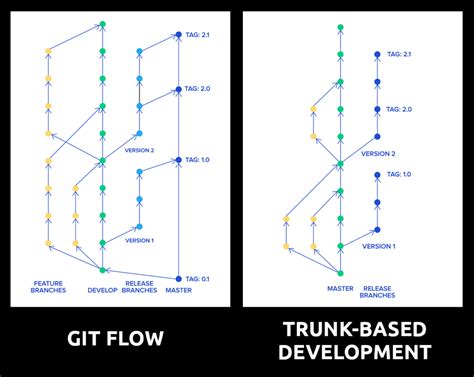
El Trunk-Based Development (TBD) es una estrategia de control de versiones que promueve la colaboración continua y la integración frecuente de cambios en una única rama principal del código, conocida como "trunk" o "main". Este enfoque busca minimizar los conflictos de integración y acelerar el ciclo de entrega de software.
El Trunk-Based Development es una práctica de gestión de control de versiones en la que los desarrolladores integran pequeños y frecuentes cambios en una rama principal compartida, denominada "trunk" o "main". A diferencia de otros enfoques como Git Flow o Feature Branching, que fomentan el uso de múltiples ramas (por ejemplo, develop, release, hotfix, feature/*), Trunk-Based Development busca simplificar el flujo de trabajo y reducir los riesgos de integración tardía.
Mientras Git Flow es útil en entornos con ciclos de lanzamiento largos y estructuras más formales, Trunk-Based Development está más alineado con metodologías ágiles y DevOps, donde la prioridad es la automatización, la productividad y la colaboración constante entre equipos.
La convención moderna recomienda usar main como nombre de la rama principal en lugar de master, por razones de claridad y neutralidad.
¿Cómo funciona Trunk-Based Development?
Esta estrategia de branching es muy curiosa puesto que no requiere el uso de ramas de larga duración. En este caso, los desarrolladores integran sus cambios a la rama tronco (suele ser main o master), de ahí su nombre, una vez al día o varias veces al día. Pero, ¡cuidado! Esta rama central debe estar lista para su despliegue en cualquier momento.
El planteamiento detrás de esta estrategia es crear un espacio de despliegue super ágil y rápido. En este sentido, los desarrolladores se ven obligados a realizar commits más pequeños y subirlos de manera continua. El principal objetivo de la estrategia Trunk-Based Development es eliminar las ramas de larga duración.
Como podemos ver, esta metodología se basa en el despliegue continuo como piedra central. Pero, en un escenario de tanto despliegue, ¿cómo se versionan los productos? Aquí es donde entran las ramas de release, que sirven para estabilizar el código sin frenar el desarrollo de la rama trunk. Imaginemos que queremos lanzar una versión mensual de nuestro producto. Unos días antes del despliegue, y para no interferir en dicha release, crearíamos la nueva rama de release que saldría del trunk. Éste sería un lugar estable donde probar y testear la release, protegiéndola del despliegue continuo al que se ve sometida la rama trunk. Una vez se trabaja en release, se ha podido avanzar sobre ella y generar algún commit nuevo que posteriormente será llevado a la rama principal con un cherry pick.
Por último, hay que destacar que esta metodología se ve muy ligada al concepto de feature flags o indicadores de características. Esta condición permite que se pueda habilitar y deshabilitar una característica específica. De esta forma, se puede subir el código nuevo de dicha característica a pesar de estar incompleto, sabiendo que la característica estará deshabilitada.
El Trunk-Based Development es una práctica obligatoria para la integración continua. Si los procesos de desarrollo y pruebas están automatizados, pero los desarrolladores trabajan en ramas de función aisladas y largas que se integran con poca frecuencia en una rama compartida, no se está aprovechando todo el potencial de la integración continua. El Trunk-Based Development disminuye la fricción de la integración del código. Cuando los desarrolladores terminan una tarea nueva, deben fusionar el código nuevo en la rama principal; pero no deben fusionar los cambios en el tronco hasta que hayan comprobado que los pueden compilar correctamente. Durante esta fase, pueden surgir conflictos si se han realizado modificaciones desde el inicio de la tarea nueva. En concreto, estos conflictos son cada vez más complejos a medida que los equipos de desarrollo crecen y la base de código se amplía. Esto ocurre cuando los desarrolladores crean ramas independientes que se desvían de la rama origen y otros desarrolladores están fusionando a la vez código que se solapa. Por suerte, el modelo de Trunk-Based Development reduce estos conflictos.
En el modelo de Trunk-Based Development hay un repositorio con un flujo constante de confirmaciones que se incorporan a la rama principal. El hecho de añadir un conjunto de pruebas automatizadas y la supervisión de la cobertura de código a este flujo de confirmaciones contribuye a una integración continua. Cuando se fusiona un código nuevo en el tronco, se ejecutan pruebas automatizadas de integración y cobertura de código para validar la calidad de dicho código.
Las rápidas y pequeñas confirmaciones del Trunk-Based Development convierten la revisión del código en un proceso más eficiente. Gracias a las ramas pequeñas, los desarrolladores podrán ver y revisar con rapidez los pequeños cambios. Esto resulta mucho más fácil en comparación con una rama de función de larga duración en la que un revisor lee páginas de código o inspecciona de forma manual una gran superficie de cambios de código.
Los equipos deben hacer fusiones a diario y con frecuencia en la rama principal. El objetivo del Trunk-Based Development es que la rama del tronco siempre tenga luz verde, de modo que siempre esté lista para la implementación con cualquier confirmación. Las pruebas automatizadas, la cobertura de código y las revisiones de código proporcionan un proyecto de Trunk-Based Development con la garantía de estar listo para hacer la implementación en producción en cualquier momento. De este modo, el equipo puede hacer implementaciones en producción con frecuencia y agilidad y fijar más objetivos para la publicación de producción diaria.
Ventajas del Trunk-Based Development
- Menos conflictos: Al integrar pequeños cambios frecuentemente, se reducen significativamente los conflictos de fusión en comparación con ramas de larga duración.
- Mayor velocidad de entrega: La integración continua y la eliminación de ramas complejas aceleran el ciclo de desarrollo y despliegue.
- Código más limpio y fácil de mantener: Un historial de cambios lineal y commits pequeños hacen que el código sea más comprensible y manejable.
- Mayor productividad: Se elimina el tiempo perdido en largas fusiones y se fomenta un flujo de trabajo más ágil.
- Retroalimentación rápida: Los desarrolladores reciben feedback sobre sus cambios de manera casi inmediata gracias a la integración continua y las pruebas automatizadas.
- Eliminación de ramas de larga duración: Se evita la complejidad y los problemas asociados con el mantenimiento de ramas que viven durante semanas o meses.
- Facilita el Despliegue Continuo (CD): La rama trunk siempre está en un estado desplegable, lo que permite realizar despliegues frecuentes y fiables.
Inconvenientes del Trunk-Based Development
- Requiere un equipo maduro y disciplinado: Es fundamental que los desarrolladores realicen commits pequeños, funcionales y bien probados.
- Necesidad de una infraestructura de CI/CD robusta: La automatización de pruebas, builds y despliegues es crucial para el éxito de esta estrategia.
- Riesgo de "romper la build": Si no se siguen las prácticas adecuadas, un commit defectuoso puede afectar a toda la rama principal.
- Gestión de Features Flags: Aunque son una herramienta poderosa, la gestión de feature flags puede añadir complejidad si no se hace correctamente.
- Ausencia de entornos de preproducción dedicados (en su forma más pura): Aunque se pueden simular, la estrategia pura se centra en la rama trunk como el entorno principal.
¿Cuándo usar Trunk-Based Development?
El Trunk-Based Development es una estrategia ideal para equipos que buscan:
- Acelerar la entrega de software.
- Implementar prácticas de Integración Continua (CI) y Despliegue Continuo (CD).
- Reducir la complejidad en la gestión de ramas.
- Fomentar una alta colaboración y comunicación dentro del equipo.
- Trabajar con metodologías ágiles como Scrum o Kanban.
Si la frecuencia con la que haces release es alta, Trunk-Based Development es la estrategia adecuada porque el proceso se convierte nada más hacer el release. ¿Se han encontrado en la situación en la que el encargado de hacer release dice "no hagan merge de nada, vamos hacer code freeze", ¿se han sentido improductivos? Es porque ¡lo es! ¿Por qué nos vamos a detener? Si tenemos una infraestructura y una suite de pruebas fuerte podemos seguir integrando y aumentar la productividad del equipo.
Prácticas recomendadas en el Trunk-Based Development
El Trunk-Based Development garantiza que los equipos publiquen el código de forma rápida y coherente. A continuación, se presenta una lista de ejercicios y prácticas que te ayudarán a perfeccionar el ritmo de trabajo de tu equipo y a desarrollar un calendario de publicaciones optimizado.
Desarrollar en lotes pequeños
El Trunk-Based Development sigue un ritmo rápido para enviar el código a producción. Si dicho desarrollo fuera como la música, se trataría de un staccato rápido: notas cortas y sucintas en rápida sucesión (si entendemos que las confirmaciones del repositorio son las notas). Al mantener un número pequeño de confirmaciones y ramas, se podrán realizar fusiones e implementaciones con más rapidez. Los pequeños cambios de un par de confirmaciones o la modificación de unas pocas líneas de código minimizan la sobrecarga cognitiva. Resulta mucho más fácil para los equipos mantener conversaciones significativas y tomar decisiones rápidas cuando se revisa un área limitada de código en lugar de un conjunto extenso de cambios.
Marcas de función (Feature Flags)
Las marcas de función complementan perfectamente el Trunk-Based Development, ya que permiten a los desarrolladores empaquetar nuevos cambios en una ruta de código inactiva y activarla más adelante. Así, los desarrolladores pueden renunciar a crear una rama de función independiente en el repositorio y centrarse en confirmar código nuevo de función directamente en la rama principal, dentro de una ruta de marca de función. Las marcas de función fomentan de manera directa las actualizaciones de lotes pequeños. En lugar de crear una rama de función y esperar a desarrollar la especificación completa, los desarrolladores pueden crear una confirmación en el tronco que introduce la marca de función y envía nuevas confirmaciones en el tronco que generan la especificación de la función dentro de la marca.
Implementar pruebas automatizadas exhaustivas
Las pruebas automatizadas son necesarias para cualquier proyecto de software moderno que pretenda alcanzar la CI y la CD. Hay varios tipos de pruebas automatizadas que se ejecutan en diferentes etapas de la canalización de lanzamiento. Las pruebas unitarias y de integración de corta duración se ejecutan durante el desarrollo y al fusionar el código. Las pruebas de extremo a extremo, de pila completa y de larga duración se ejecutan en fases posteriores de la canalización en un entorno completo de ensayo o producción. Las pruebas automatizadas facilitan el Trunk-Based Development al mantener un ritmo de lotes pequeños a medida que los desarrolladores fusionan confirmaciones nuevas. La serie de pruebas automatizadas revisa el código para detectar cualquier incidencia y lo aprueba o rechaza automáticamente. Esto ayuda a los desarrolladores a crear rápidamente confirmaciones y ejecutarlas a través de pruebas automatizadas para ver si introducen incidencias nuevas.
Realizar revisiones de código asíncronas
En el Trunk-Based Development, el código no se puede colocar en un sistema asíncrono para revisarlo más tarde; hay que revisarlo de inmediato. Las pruebas automatizadas proporcionan una capa de revisión de código preventiva. Cuando los desarrolladores están listos para revisar la solicitud de incorporación de cambios de un miembro del equipo, en primer lugar, pueden comprobar que las pruebas automatizadas se han superado y que la cobertura del código ha aumentado, lo que da al revisor la seguridad inmediata de que el código nuevo cumple especificaciones determinadas y se podrá centrar en optimizarlo.
Tener tres o menos ramas activas en el repositorio de código de la aplicación
Una vez que una rama se fusiona, se recomienda eliminarla. Un repositorio con una gran cantidad de ramas activas provoca una serie de efectos colaterales un tanto inoportunos. Aunque el hecho de poder ver qué tarea está en curso analizando las ramas activas resulta ventajoso para los equipos, dicha ventaja se pierde si hay ramas inactivas y obsoletas. Algunos desarrolladores utilizan interfaces de usuario de Git que pueden llegar a ser difíciles de manejar al cargar un gran número de ramas remotas.
Fusionar las ramas con el tronco al menos una vez al día
Los equipos de desarrollo por tronco de alto rendimiento deben cerrar y fusionar al menos una vez al día cualquier rama que haya abierta y lista para fusionar. Este ejercicio ayuda a mantener el ritmo y marca una cadencia para la supervisión de las publicaciones. Los equipos pueden etiquetar el tronco principal al final del día como confirmación de publicación, lo cual contribuye a crear un incremento ágil diario.
Reducir el número de bloqueos de código y fases de integración
Los equipos que siguen la metodología ágil y aplican las técnica de CI y CD no deberían tener que planificar bloqueos o pausas del código para las fases de integración, aunque una organización puede requerirlo por otros motivos. El adjetivo “continua” en CI y CD implica que las actualizaciones fluyen constantemente. Los equipos de Trunk-Based Development deben tratar de evitar el bloqueo del código y planificar en consecuencia para garantizar que el proceso de publicación no se estanque.
Compilar rápido y ejecutar de inmediato
Para mantener un ritmo rápido de publicaciones, hay que optimizar los tiempos de compilación y ejecución de pruebas. Las herramientas de compilación de CI y CD deberían utilizar capas de almacenamiento en caché cuando sea apropiado para evitar procesados costosos del contenido estático. Las pruebas se deben optimizar para utilizar los códigos auxiliares (stubs) adecuados para los servicios de terceros.
¿Trabajando en MAIN? - Trunk based development.
Conclusión
El Trunk-Based Development es actualmente el estándar para los equipos de ingeniería de alto rendimiento, ya que establece y mantiene un ritmo de publicación de software mediante el uso de una estrategia de creación de ramas Git simplificada. Además, el Trunk-Based Development ofrece a los equipos de ingeniería más flexibilidad y control sobre la forma de lanzar el software para el usuario final.